






星标“医工学人”,第一时间获取医工交叉领域新闻动态~


“Anthropic 的 Claude 3 系列在评估的人工智能模型中表现出最高的准确率,超过了人类的平均准确率,人类的集体决策则优于所有人工智能模型。GPT-4 Vision Preview 表现出选择性,用较小的图像和较长的问题更多地回答较容易的问题。”

NEJM图像挑战数据集与响应能力
该研究的数据显示,自 2005 年 10 月 13 日开始的 NEJM 图像挑战赛参与度很高,截至 2023 年 12 月 13 日,945 例病例共收到超过 8500 万份回复。每个问题的平均回复数为 90,679(SD = 32,921;中位数 = 88,407;范围 = 13,120–233,419)。正确回答医疗病例的平均投票百分比为 49.4%(SD = 13.6%;中位数 = 49%;范围 = 16–88%),反映了病例问题固有的不同难度级别。问题的长度从 4 到 128 个字不等,平均为 28.5 个字,表明提供的额外临床信息范围各不相同。NEJM 图像挑战赛中分析的医学图像的分辨率范围很广,大小从 0.57 到 5.95 兆像素不等。这些图像的平均分辨率为 202 万像素,这表明,向 AI 模型和公众呈现的图像细节和质量存在相当大的差异。
虽然所有开源模型以及 Anthropic 的 Claude 3 系列专有模型都回答了所有查询,但专有的 GPT-4 Vision Preview(例如,“抱歉,我无法提供医学诊断或解释医学图像。[…]”)仅回答了 76%(n = 718)的案例。GPT-4 Vision Preview 更倾向于回答以人类参与者平均正确率(p = 0.033)衡量的较简单的问题,以及图像较小(p < 0.001)和问题文本较长(p < 0.001,图1)的问题。Bard Gemini 1.0 Vision Pro 仅因未知原因(“block_reason:OTHER”)未能回答一个问题(0.11%)。
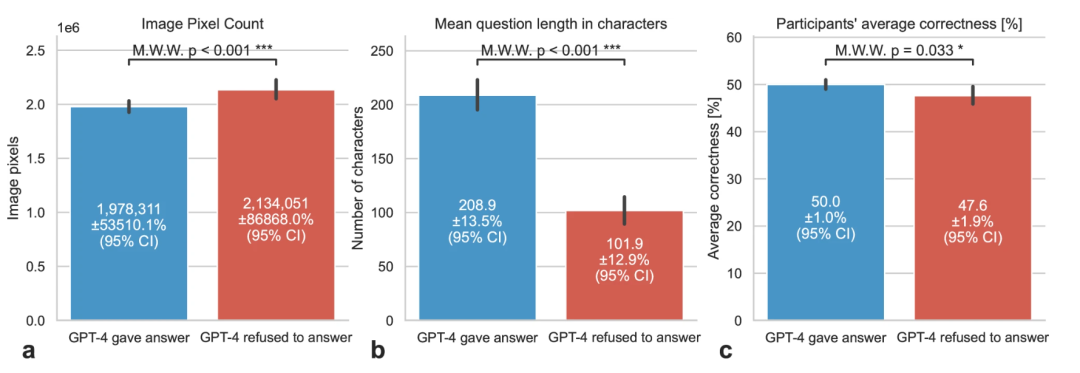
图 1:GPT-4V 答案状态与图像像素数、问题长度和参与者平均正确率。(来源:npj digital medicine)
准确性与GPT-4V回答问题的选择性
在所有 AI 模型中,Anthropic 模型脱颖而出,实现了最高的准确率( 在 945 个问题中的58.8% (n = 556 个)到 945 个问题中的59.8% (n = 565 个)之间),大大超过了参与者的平均投票数(49.4%, p < 0.001)约 10%。该研究观察到,由多数票决定的集体人类决策(其中 7 个平局算作错误答案)正确回答了 90.8%(n = 858)的病例,揭示了群体智能在医学多模态诊断方面的能力,并且大大超越了所有测试过的多模态模型(图2)。
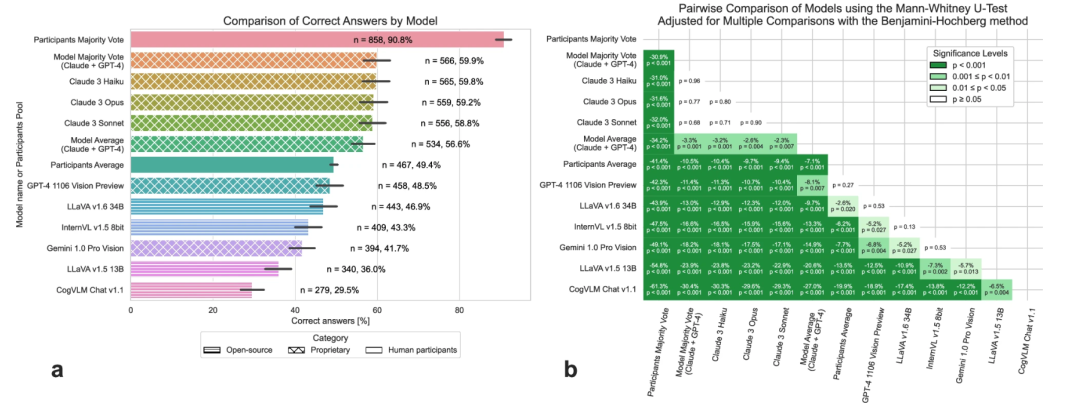
图 2:多模态模型在医学图像分析中的准确性(来源:npj digital medicine)
人工智能在医疗诊断中的能力
所有 Claude 3 模型在正确性方面都超越了 OpenAI 的 GPT-4 Vision Preview,并且没有否认任何问题,这可能表明 Anthropic 的训练方法更加一致。总的来说,该研究已经表明通用模型非常适合回答高度具体的医学知识问题,甚至超过了参与者的平均正确率。
在该研究中,Claude 3 Haiku 获得了最高的准确率。在另一项研究中也观察到了类似的结果,其中纯文本的 GPT-4 在诊断 NEJM 病例1时优于 99.98% 的模拟人类读者——尽管只包含 38 个病例,这一结果在使用 GPT-4 Vision Preview 进行的多模态图像挑战分析中没有复制。人类集体智慧以 90.8% 的准确率超越了所有 AI 模型,这与 James Surowiecki 提出的概念一致。
总体而言,这些发现对 AI 在医学诊断领域的未来充满希望,特别是在皮肤病学等领域,癌症检测的自动化正显示出越来越多的科学兴趣。最近发表的一项荟萃分析表明,人工智能检测皮肤癌的准确率大大超过全科医生,且表现可与经验丰富的皮肤科医生相媲美。
此外,另一项分析发现,使用人工智能模型可以实现 90% 以上的皮肤癌检测准确率。这些结果表明,人工智能在特定诊断任务(如皮肤癌检测)中的分析能力大大超过在更一般的多模态分析中观察到的能力。事实证明,由于实施不一致,旨在防止非专业人员进行自我诊断的安全机制不足 。该研究和其他研究的结果表明,虽然人工智能可以显著支持医疗诊断和培训并简化医疗服务,但将其融入临床实践需要采取谨慎、认真和透明的方式,并必须进行监管监督。
就在最近,欧盟议会通过了《欧盟人工智能法案》,这是一项具有里程碑意义的立法,旨在通过根据风险级别对人工智能应用进行分类来规范人工智能。该法案对高风险人工智能系统(包括医疗保健领域使用的系统)提出了严格的要求。
该法规要求透明度、稳健性和人工监督,确保人工智能系统安全且合乎道德地运行。对于医疗人工智能,《欧盟人工智能法案》强调人工智能决策过程必须有清晰的记录、可追溯性和可问责制。它还强调了严格测试和验证以满足高准确性和可靠性标准的重要性。
该研究中分析的开放模型在这里具有明显的优势,因为它们具有公开可用的模型权重,并且通常有所使用的训练代码和数据集的良好记录,从而促进了《欧盟人工智能法案》所要求的透明度和可追溯性。
▼扫码阅读英文原文

npj Digit. Med. 7, 205 (2024).
doi.org/10.1038/s41746-024-01208-3
*文章仅为分享医工交叉领域前沿技术及动态,无任何利益关系。如涉及版权问题,请联系我们删除。
欢迎文末留言参与讨论~
END
编辑 | 杨炳乾
参考 | npj Digital Medicine
审核 | 医工学人理事会
扫码注册加入医工学人,进入综合及细分领域群聊,参与线上线下交流活动

*声明:医工学人为公益性非盈利组织,不收取任何注册费用
推荐阅读
穿戴未来:探索可穿戴超声设备的革命性应用 | 顶刊一文盘点(上)
点击关注医工学人


本篇文章来源于微信公众号: 医工学人
