








为回答这个问题,GMAI 团队构建了一个大规模的跨数据集腹部多器官分割 Benchmark——A-Eval,并尝试从数据中心和模型规模两个视角来揭示影响模型泛化性的关键因素和最佳实践。
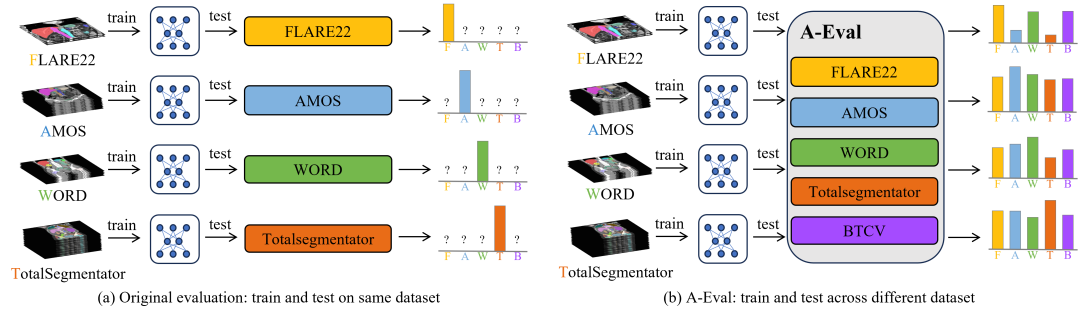
图1:对比传统的评测和 A-Eval benchmark。(a)传统的评测在相同的数据集上划分训练集和测试集来评估模型性能。(b)A-Eval 在不同的数据集上进行训练和测试,提供更全面的模型性能验证以及模型泛化性的评估。
论文:
https://arxiv.org/abs/2309.03906
开源代码:
https://github.com/uni-medical/A-Eval
Benchmark的构建
A-Eval 的构建基于 5 个公开的腹部多器官分割数据(FLARE22, AMOS22, WORD, TotalSegmentator),其中 4 个大规模数据集的训练集被用来训练模型,这 4 个数据集的验证集以及 BTCV 的训练集一共 5 个数据集被用来测试。由于不同的数据集所涵盖的类别有所不同,为了保证测评的一致性,我们选择了 5 个数据集共有的 8 类腹部器官进行评测。
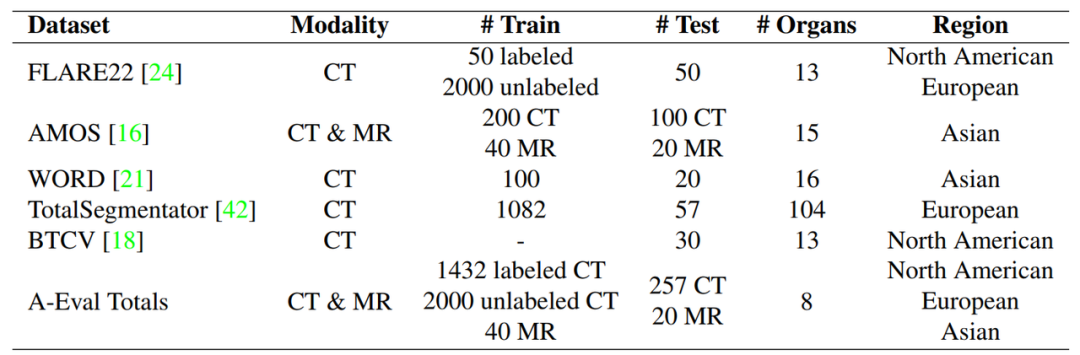
图2:A-Eval 使用的数据集介绍,其中使用到了 4 个数据集(FLARE22, AMOS, WORD, TotalSeg)的官方训练集进行训练,使用 4 个数据集的官方验证集以及 BTCV 的官方训练集进行测试。

图3:A-Eval 所使用的 5 个数据集包含的类别展示,A-Eval 选择了 5 个数据集都包含的 8 类腹部器官进行测评。(点击查看大图)
实验结果
我们对比了在四个大规模数据集上单独训练模型和在四个数据集上联合训练模型的结果,进行单独训练模型时,我们进一步考虑了以下情况:仅使用FLARE22 数据集的有标注数据和同时使用标注数据和伪标注数据两种情况;仅使用AMOS 的 CT 数据,仅使用 MR 数据和同时使用 CT 和 MR 数据训练三种情况。模型统一使用 STU-Net-L,评测指标使用 DSC 和 NSD。数值结果和可视化结果如下:

图4:在 A-Eval 上,各种不同的训练数据下,模型的跨数据集泛化性数值结果对比。(点击查看大图)
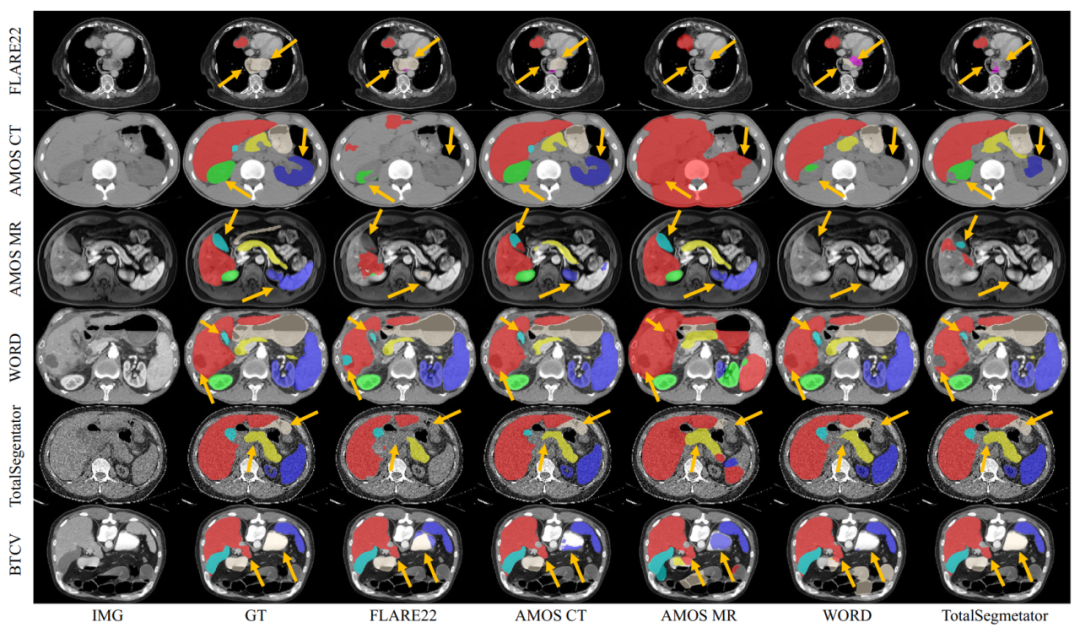
图5:不同的训练数据集上,跨数据集泛化效果的可视化对比。
可以发现以下结论:
1. 在同一数据集上训练的模型,在该数据集的测试数据上,效果要好于其它数据集上训练的模型,从可视化图中可看到。
2. 仅对比在有标注的 CT 数据上训练的模型时,它们的跨数据集泛化性有如下规律:FLARE22(50)<WORD(100)<AMOS(200)<TotalSegmentator(1082)。这符合随着数据规模越大,泛化性越好的规律。
3. 大量伪标签数据的使用,相比仅使用少量的有标注数据,能大幅提高模型的泛化性。
4. 结合多模态数据训练(CT, MR),比单一模态训练的模型,具有更好的泛化性。
5. 联合所有数据集训练的模型,具有最强的泛化性。
另外我们对比了模型大小对模型泛化性的影响,使用了 4 种不同大小的 STU-Net 模型:
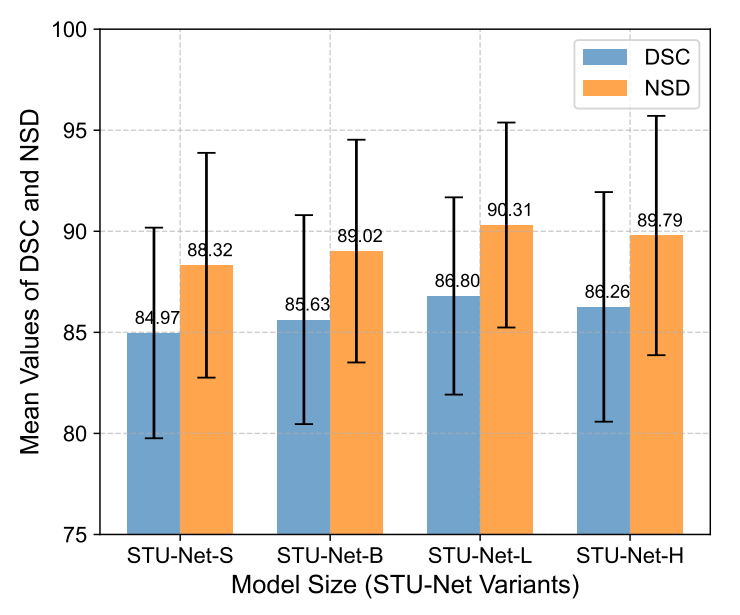
图6:不同大小模型的跨数据集泛化性对比。
可以看到,增加模型大小可以在一定程度上提高模型的泛化性。但是对于腹部多器官分割任务而言,过大的模型尺寸可能会造成过拟合,反而会降低模型的泛化性。
总结
本文介绍了 A-Eval,一个用于评测腹部多器官分割模型的跨数据集泛化能力的大规模 Benchmark。基于 A-Eval, 我们以数据为中心,评测了模型在各种不同的训练数据上训练所表现出的跨数据集泛化性,发现使用较大的训练数据集、通过伪标签整合未标记数据、采用多模态学习和跨多个数据集的联合训练都可以显著提高模型的跨数据集泛化能力。此外,我们的实验结果表明,适当增加模型的大小可以带来更好的性能,从而凸显了大型模型在提高泛化能力方面的潜力。
END
来源 | 通用医疗GMAI
编辑 | 罗虎
审核 | 医工学人


本篇文章来源于微信公众号: 医工学人
