






星标“医工学人”,第一时间获取医工交叉领域新闻动态~


美国华盛顿大学(University of Washington)Tuochao Chen, Malek Itani,Shyamnath Gollakota等提出了一种产生声音气泡的智能耳机系统。他们称之为 Sound Bubble,能够抑制 1-2 米虚拟气泡之外的任何噪音,为内部的平静对话提供条件。相关研究工作以“Hearable devices with sound bubbles”为题发表于《Nature Electronics》。

人类听觉系统在拥挤的环境中感知距离和区分说话人的能力有限。一种可以产生音泡的耳机技术,其中气泡内的所有扬声器都可以听到,但气泡外的扬声器和噪音被抑制,可以增强人类的听觉。然而,开发此类技术具有挑战性。
美国华盛顿大学Tuochao Chen等人提出的带有内置 AI 的特殊耳机,他们称之为 Sound Bubble。能够抑制 1-2 米虚拟气泡之外的任何噪音,为内部的平静对话提供条件。
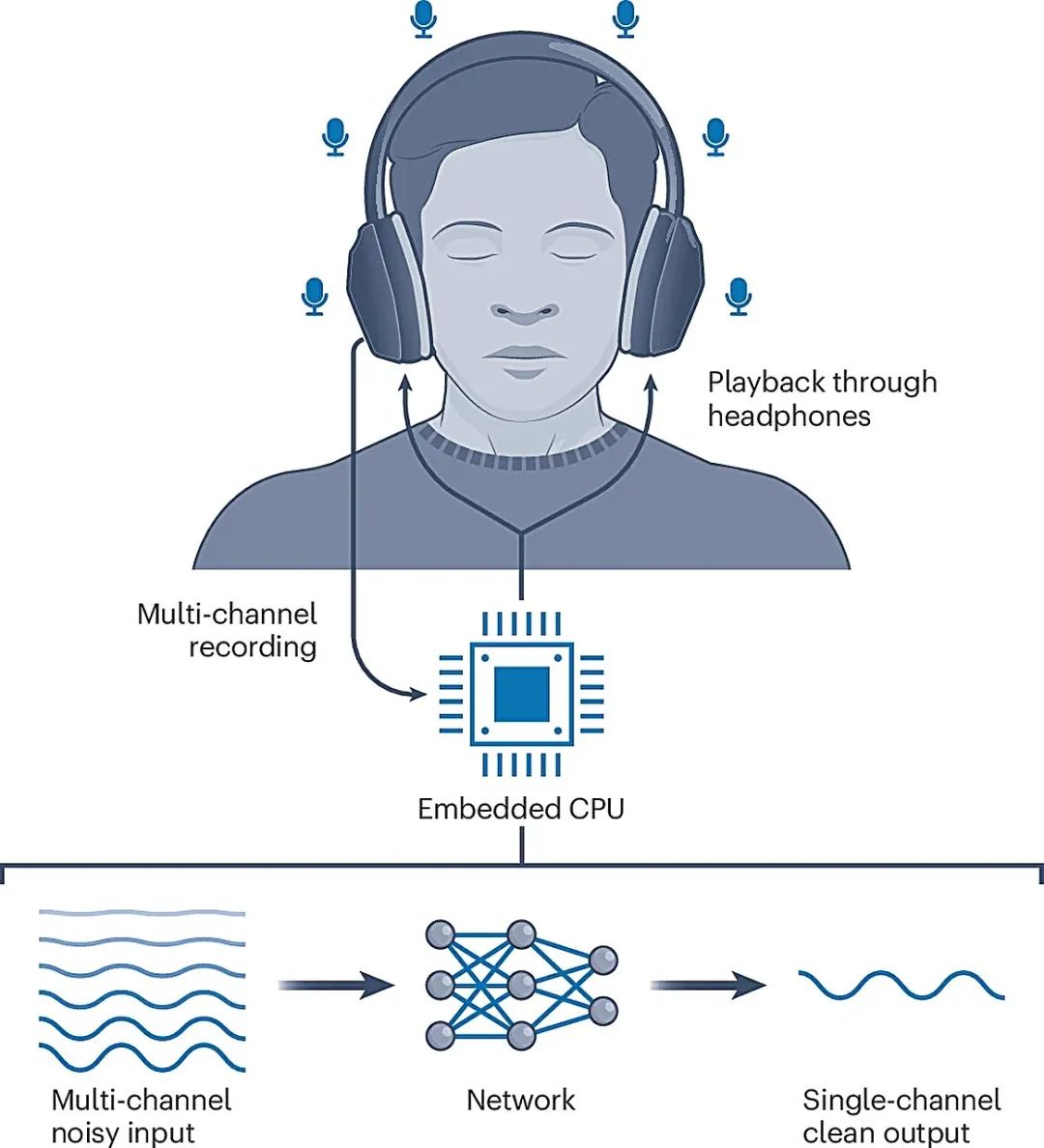
耳机技术。图片来源:Nature Electronics (2024)

利用可听戴设备,创建声音气泡
研究人员使用市售的降噪耳机创建了原型。他们在头带上贴了六个小麦克风。该团队的神经网络在连接到耳机的小型板载嵌入式计算机上运行,可跟踪不同声音何时到达每个麦克风。

合成数据评估
“我们之前使用过一个智能扬声器系统,将麦克风分散在桌子上,因为我们认为麦克风之间需要很长的距离才能提取有关声音的距离信息,”Gollakota 说。
“但后来我们开始质疑我们的假设。我们需要一个大的分离来创造这个 “声音气泡” 吗?我们在这里表明的是,我们没有。我们能够只用耳机上的麦克风实时完成,这真是令人惊讶。
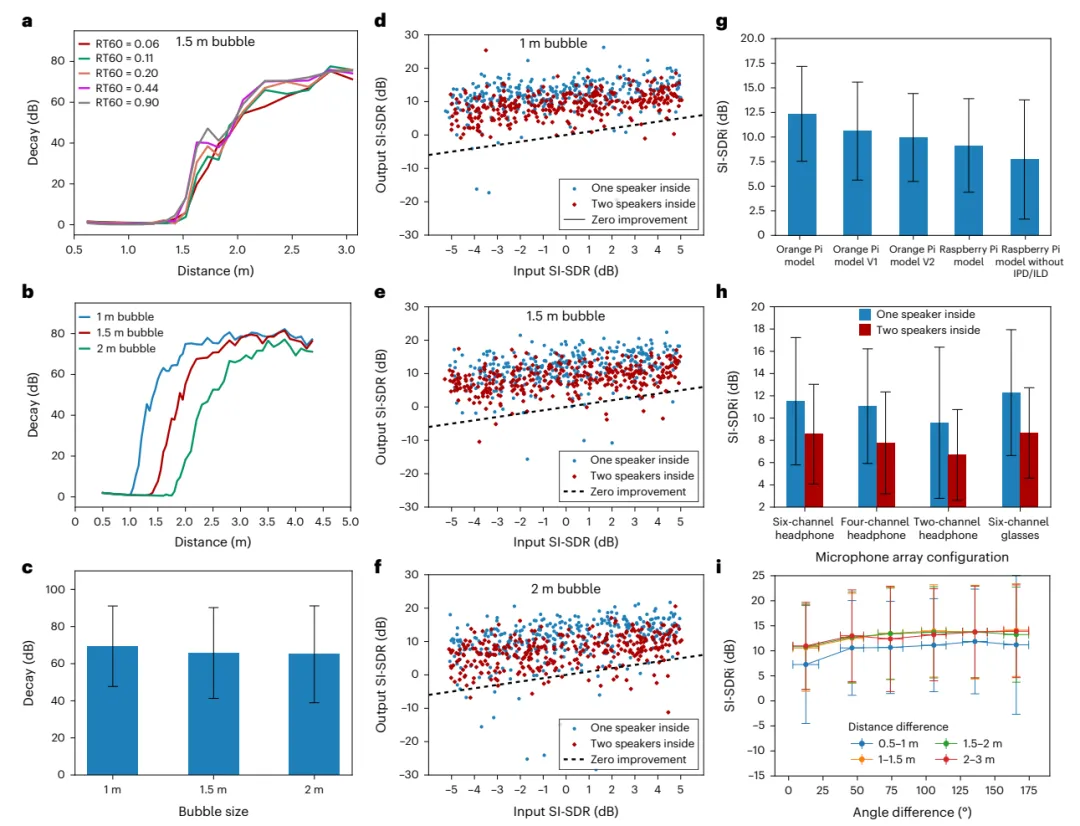
合成数据评估
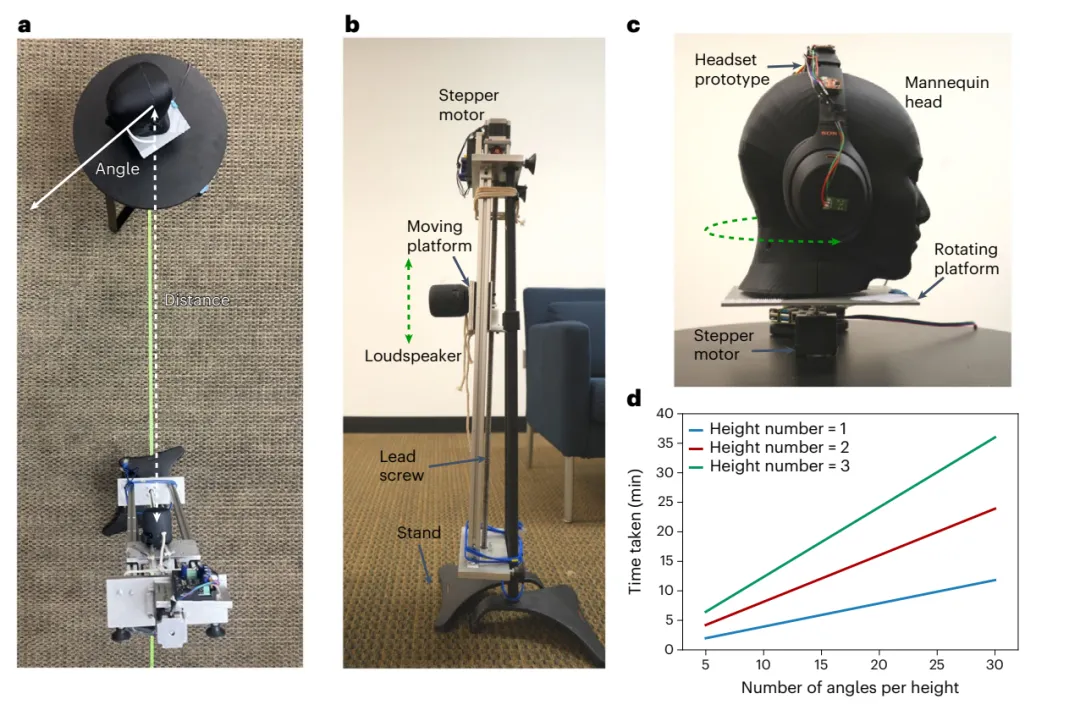
用于真实世界数据收集的机器人平台
为了训练系统在不同环境中创建气泡,研究人员需要一个在现实世界中收集的基于距离的声音数据集,而该数据集不可用。为了收集这样的数据集,他们将耳机戴在人体模型头上。
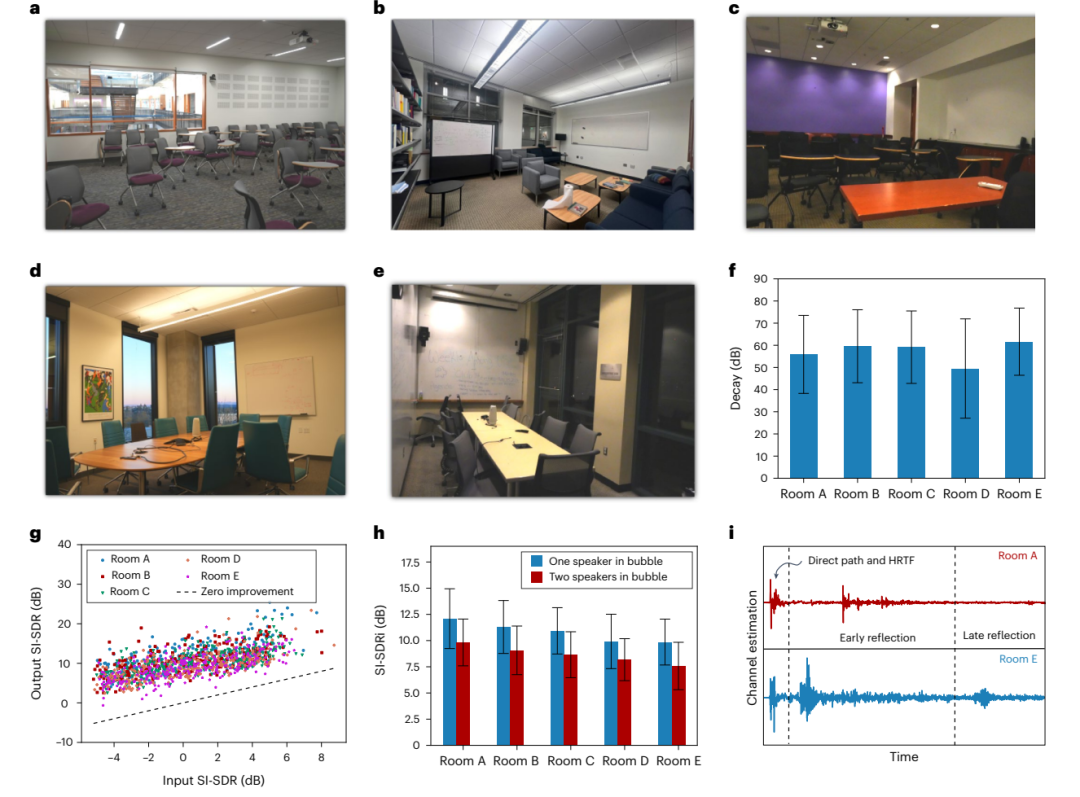
真实世界评估
机器人平台旋转头部,同时移动的扬声器播放来自不同距离的噪音。该团队使用人体模型系统以及 22 个不同室内环境(包括办公室和生活空间)中的人类用户收集数据。
研究人员已经确定该系统有效有几个原因。首先,佩戴者的头部会反射声音,这有助于神经网络区分来自不同距离的声音。其次,声音(如人类语音)具有多个频率,每个频率在从源头传播时都会经历不同的阶段。
研究人员认为,该团队的 AI 算法正在比较每个频率的相位,以确定任何声源(例如,一个人在说话)的距离。
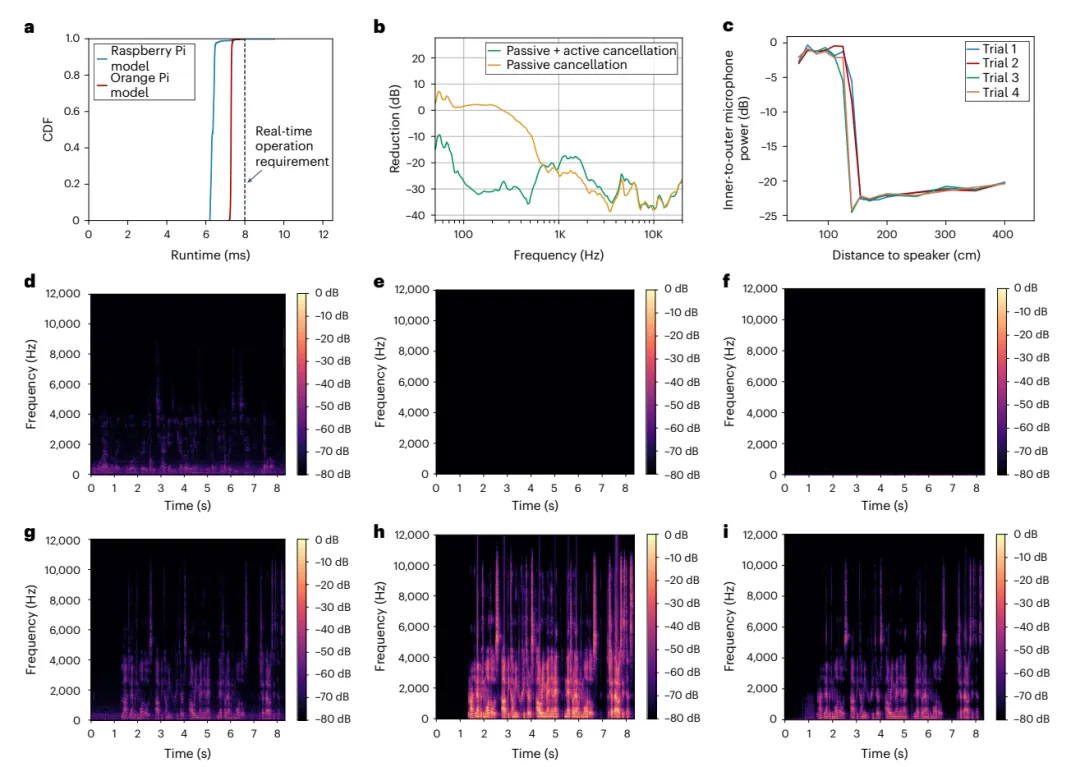
降噪耳机的端到端实时集成
像 Apple 的 AirPods Pro 2 这样的耳机可以放大佩戴者面前人的声音,同时减少一些背景噪音。但这些功能的工作原理是跟踪头部位置并放大来自特定方向的声音,而不是测量距离。这意味着耳机无法同时放大多个扬声器,如果佩戴者将头从目标扬声器上移开,耳机就会失去功能,并且在减少来自扬声器方向的响亮声音方面效果不佳。
该系统已经过训练,只能在室内工作,因为在室外更难获得干净的培训音频。接下来,该团队正在努力使该技术在助听器和降噪耳塞上发挥作用,这需要一种新的麦克风定位策略。
文章链接:
https://www.nature.com/articles/s41928-024-01276-z
扫码注册加入医工学人,进入综合及细分领域群聊,参与线上线下交流活动

*声明:医工学人为公益性非营利组织,不收取任何注册费用,申请审核通过后将以邮件通知
推荐阅读
点击关注医工学人

本篇文章来源于微信公众号: 医工学人
