






-
标题:CLIP in Medical Imaging: A Comprehensive Survey
-
DOI:arXiv:2312.07353
-
作者:上海科技大学生物医学工程学院沈定刚团队
-
Github:https://github.com/zhaozh10/Awesome-CLIP-in-Medical-Imaging (点击原文链接,欢迎交流star!)
-
关注公众号,回复【CLIP-20231213】获论文PDF最新版。
1 摘要
1 摘要
-
从对CLIP方法论基础的简要介绍开始。 -
然后,我们调查了CLIP预训练在医学领域中的应用,重点关注如何优化CLIP以适应医学图像和报告的特征。 -
此外,我们探讨了在各种任务中实际利用CLIP预训练模型的可能性,包括分类、密集预测和跨模态任务。 -
最后,我们讨论了CLIP在医学影像背景下现存的局限性,并提出了前瞻性的方向,以满足医学影像领域的需求。我们期望这份全面的调查将为医学图像分析领域的研究人员提供对CLIP范式及其潜在影响的整体理解。 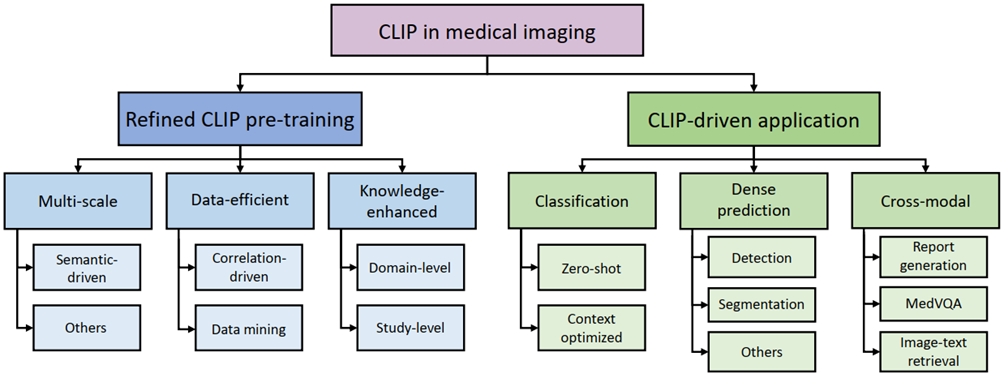
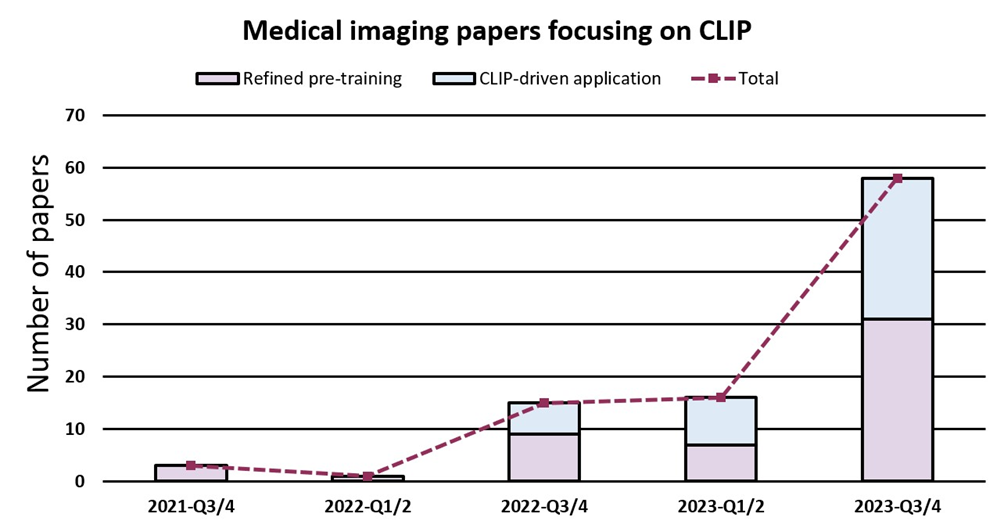 图2. 近年来专注于CLIP在医学影像领域的论文数量。我们按时间顺序对这些论文进行了分类(Q代表季度),显示出了指数增长的趋势。
图2. 近年来专注于CLIP在医学影像领域的论文数量。我们按时间顺序对这些论文进行了分类(Q代表季度),显示出了指数增长的趋势。
2 介绍
2 介绍
1.1 动机和贡献
-
据我们所知,本文是对医学影像中CLIP现状的首次全面回顾,旨在为这个快速发展的领域的潜在研究提供及时的见解。 -
我们全面覆盖了现有研究并提供了多层次的分类体系,以满足潜在研究的不同需求,如图1所示。对于精细预训练,我们重点介绍了大多数现有研究解决的关键挑战,而对于CLIP驱动的应用,考虑到其涉及任务的性质,我们进一步对其进行了分类。 -
此外,我们讨论了与现有研究相关的问题和未解决的方面。我们指出了新的趋势,提出了重要问题,并提出了未来探索的方向。
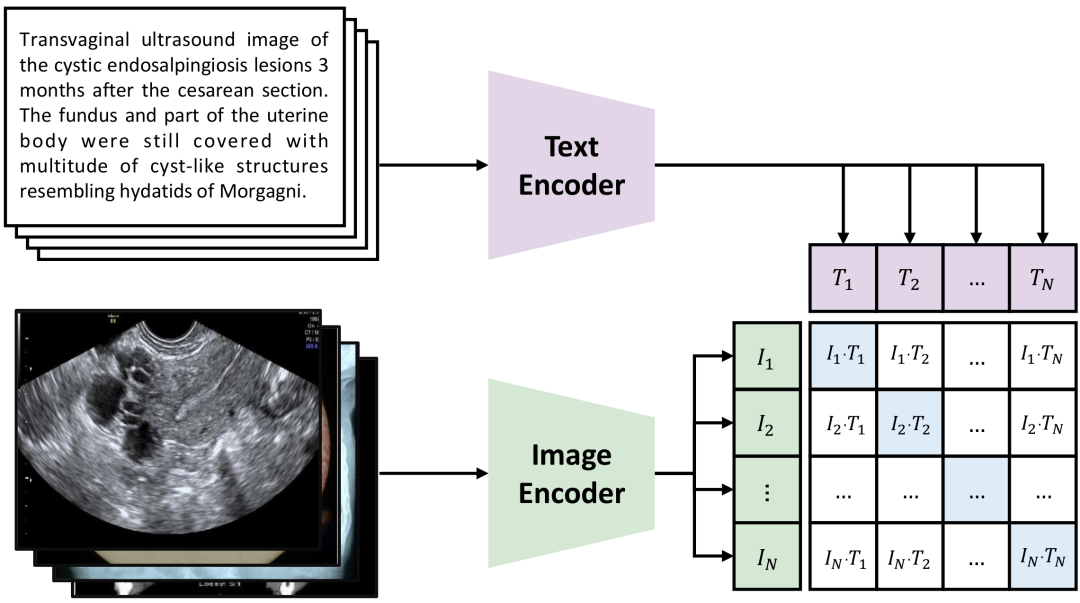 图3. CLIP框架的示例(基于PMC-OA数据集)。
图3. CLIP框架的示例(基于PMC-OA数据集)。
1.2 论文组织。
-
第2节提供了CLIP及其一些变体的初步知识。 -
第3节中,我们从关键挑战和相应解决方案的角度,系统地分析了如何将CLIP预训练应用于医学成像领域。 -
第4节涵盖了预先训练的CLIP在几种临床相关任务中的各种应用,并提供了CLIP驱动方法与先前的知识驱动或纯数据驱动方法之间的比较。 -
第5节讨论存在的问题和潜在的研究方向,为感兴趣的研究者提供见解。 -
第6节对本文进行总结。
2 背景:
2.1 架构方面
2.2 对比预训练
2.3 零样本学习能力
2.4 CLIP 的通用性
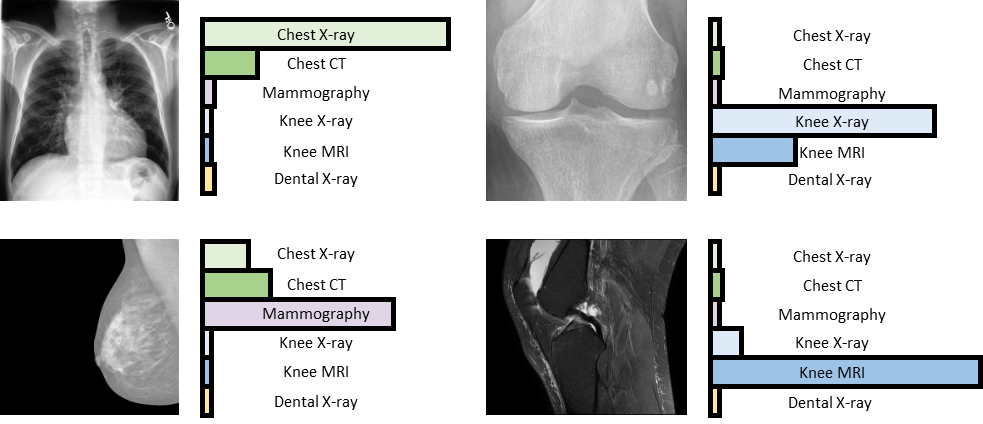
2.5 CLIP的变体
2.6 医学图文数据集
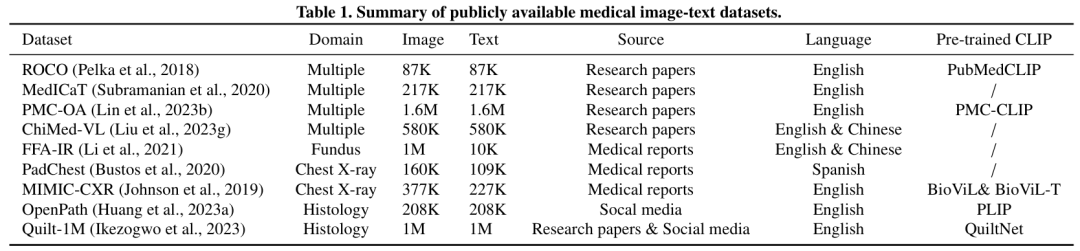 表 1. 公开可用的医学图像文本数据集摘要。
表 1. 公开可用的医学图像文本数据集摘要。
3 针对医学图像改进的CLIP预训练
3 针对医学图像改进的CLIP预训练
3.1. CLIP预训练的挑战
3.1.1 多尺度特征
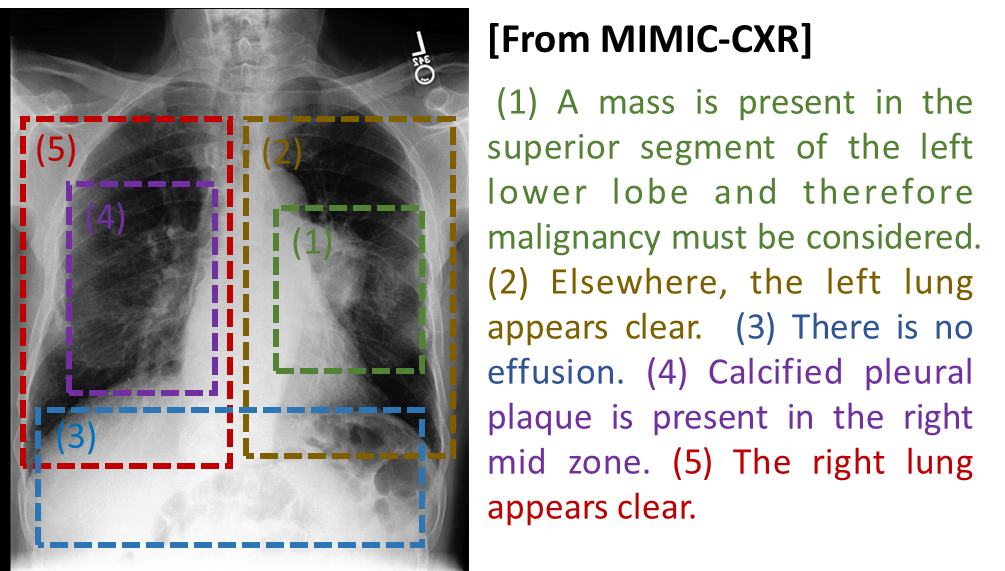
3.1.2 数据稀缺
3.1.3 较高的专业知识要求
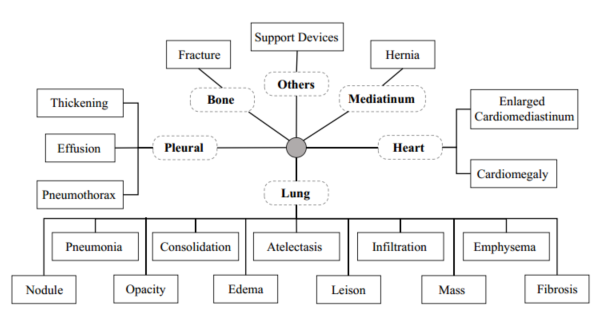
3.2 多尺度对比
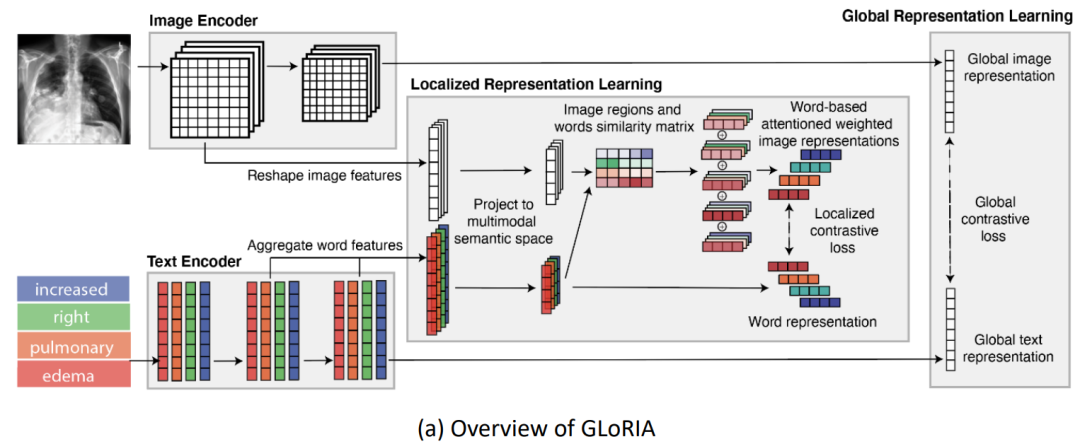
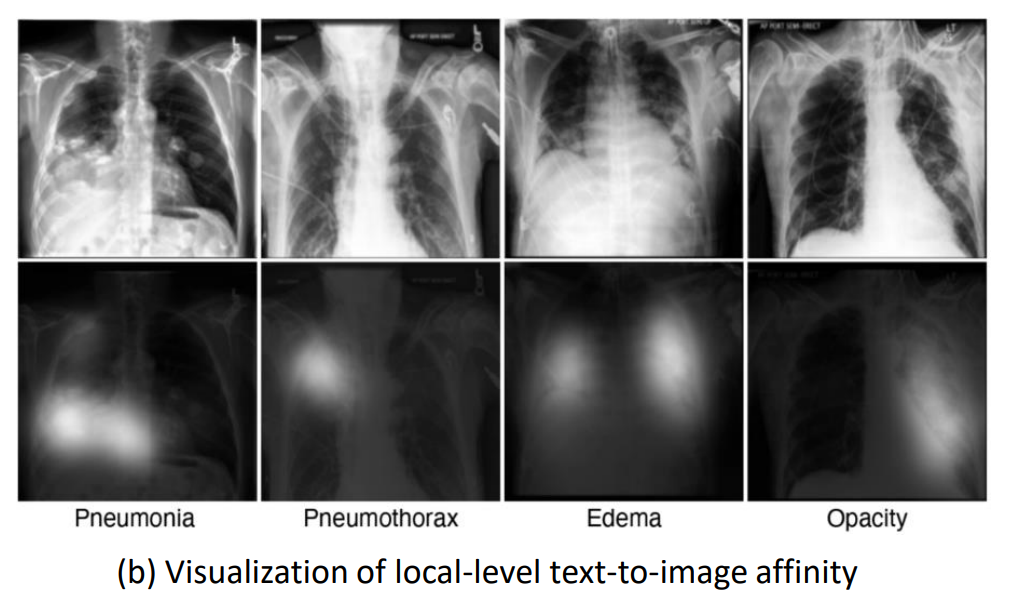 图7. GLoRIA(Huang等人,2021)提出的语义驱动对比的插图。(a) GLoRIA的概述,它基于跨模态语义亲和力执行多尺度图像文本对齐。全局级别的对齐通常遵循CLIP的方法,而局部级别的对比目标在注意力加权的图像表示和相应的单词表示之间进行优化。(b) GLoRIA学到的语义亲和力的可视化。
图7. GLoRIA(Huang等人,2021)提出的语义驱动对比的插图。(a) GLoRIA的概述,它基于跨模态语义亲和力执行多尺度图像文本对齐。全局级别的对齐通常遵循CLIP的方法,而局部级别的对比目标在注意力加权的图像表示和相应的单词表示之间进行优化。(b) GLoRIA学到的语义亲和力的可视化。
3.3 数据高效式对比
3.3 数据高效式对比
3.3.1 基于样本互相关的对比
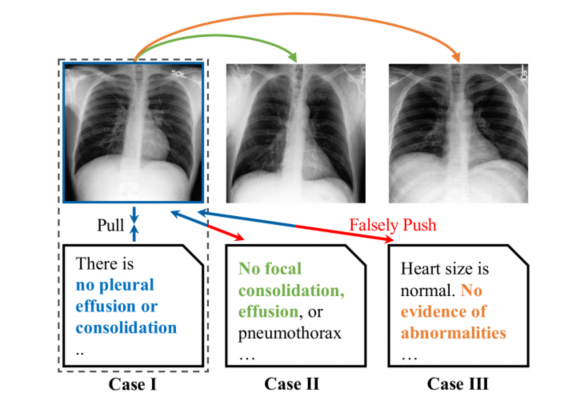
3.3.2 数据增强式预训练
3.4 知识增强
3.5 总结
-
多尺度对比:这种方法专注于在微观层面上实现一致性,具体而言,是在图像内的局部级别特征之间。这不仅仅是将图像与文本匹配,而是确保图像内的细节在医学背景下是一致且有意义的。 -
数据高效式对比:这里的重点是维持不同样本之间关系的一致性。该方法利用样本间的相关性,目标是在数据较少的情况下也能实现更多。这在医学数据稀缺或难以获得的情况下尤其有价值。 -
知识增强:这些方法努力与专家级医学知识保持一致。这种方法不仅仅是在表面上匹配图像和文本,还涉及确保关联和解释与专家所具有的更深层次、往往复杂的医学理解一致。
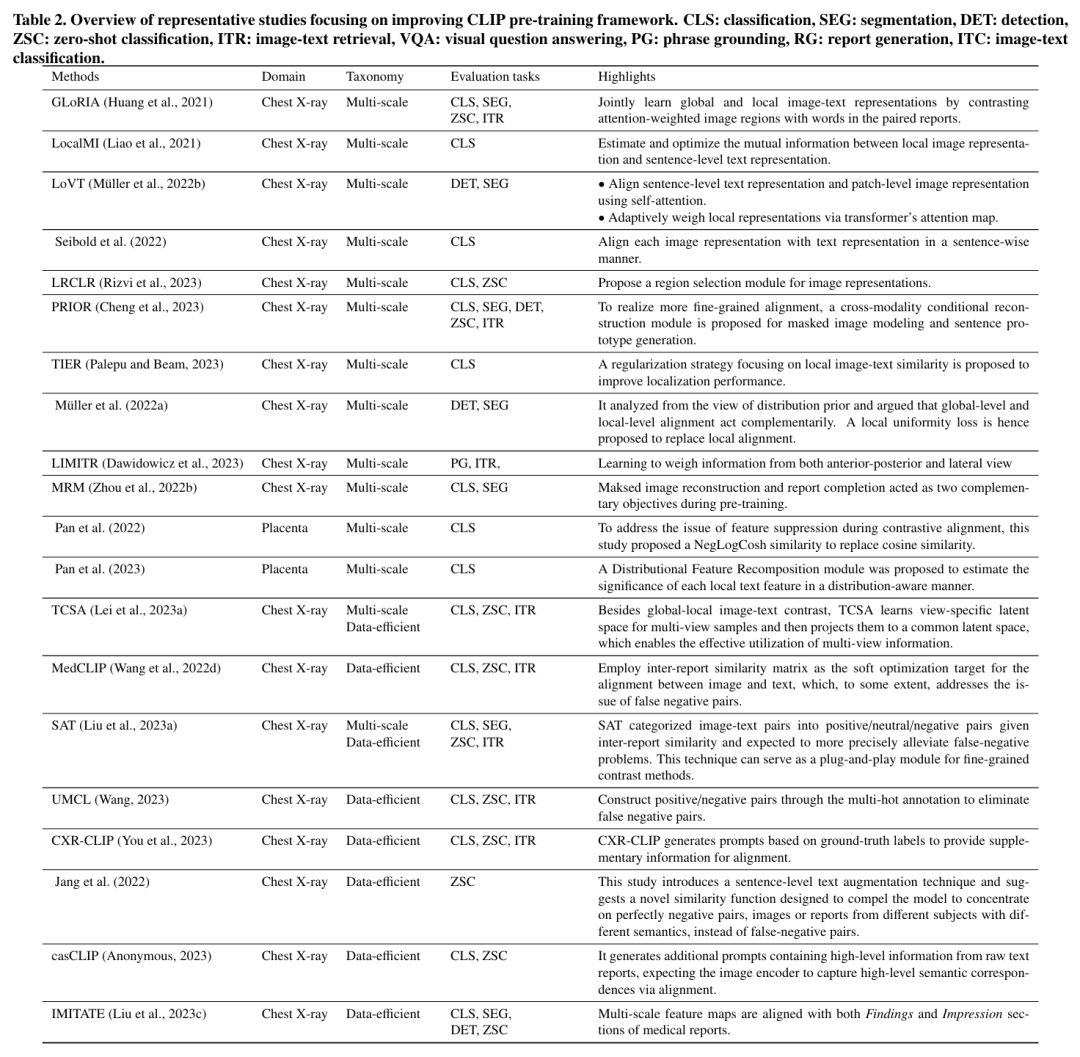
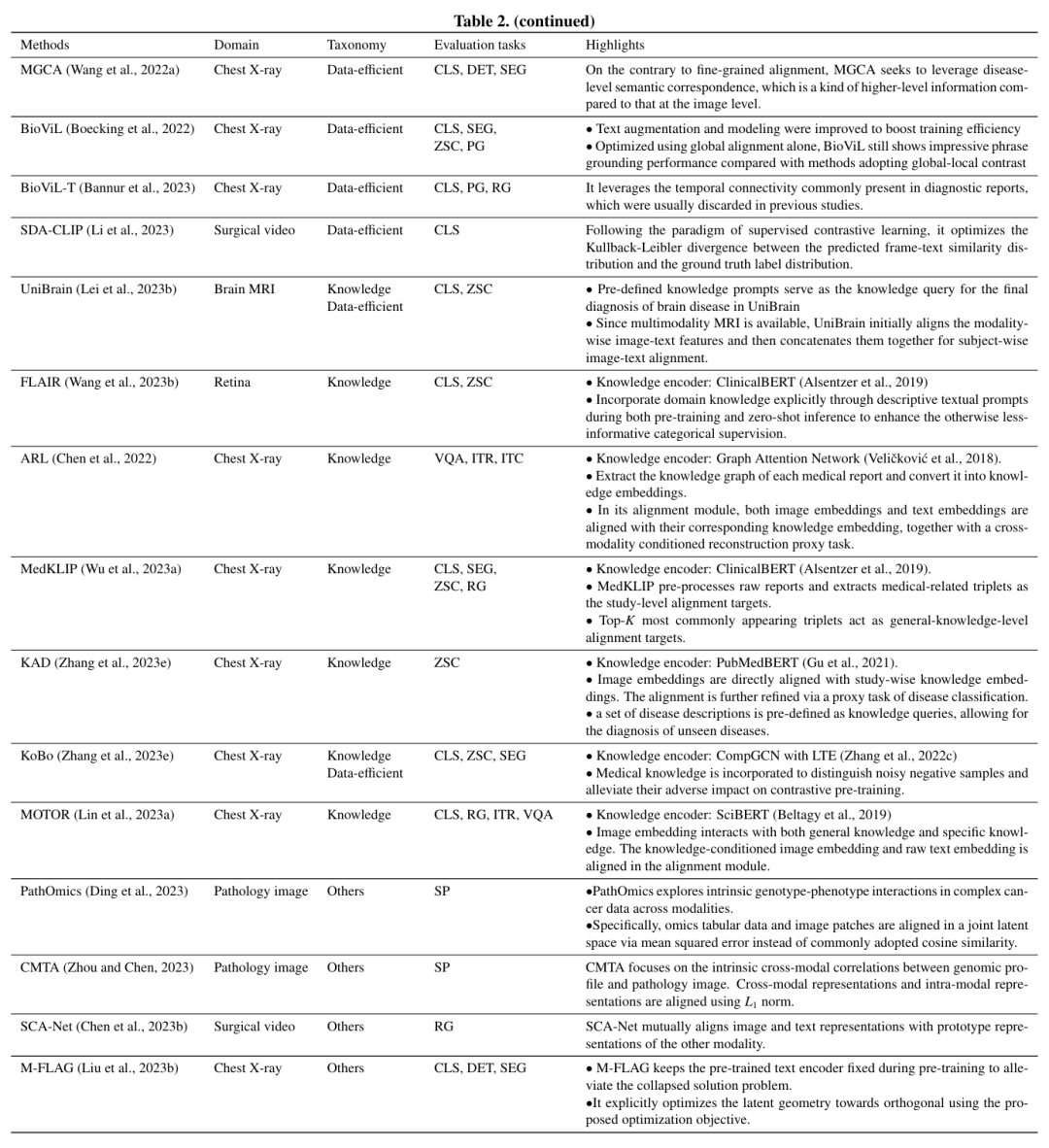
4 CLIP驱动的计算机辅助诊断方法
4.1 分类
4.1.1 零样本分类
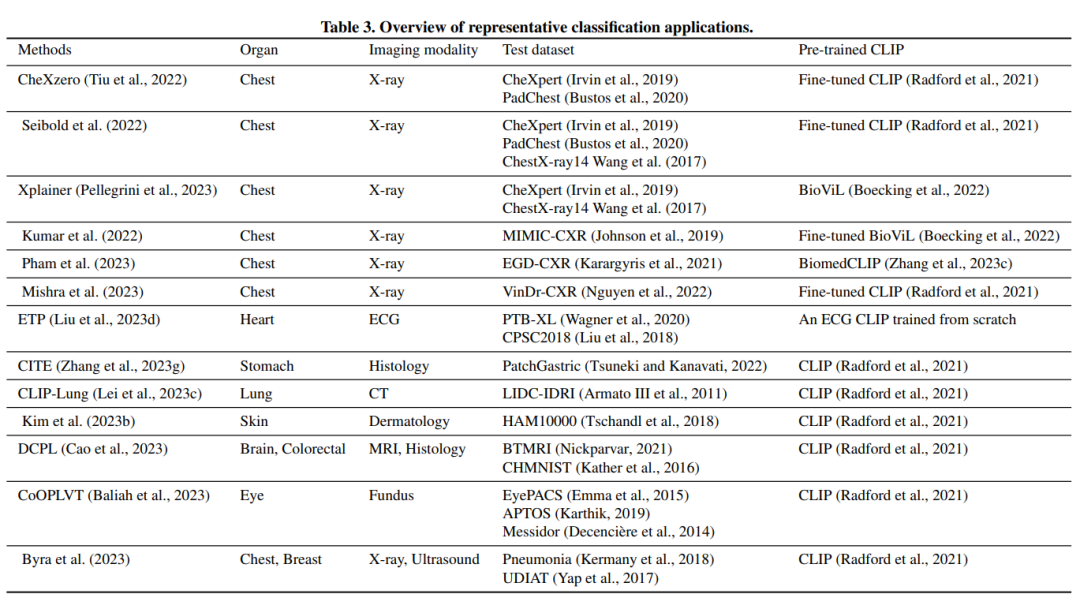 表3.代表性分类应用概述。
表3.代表性分类应用概述。
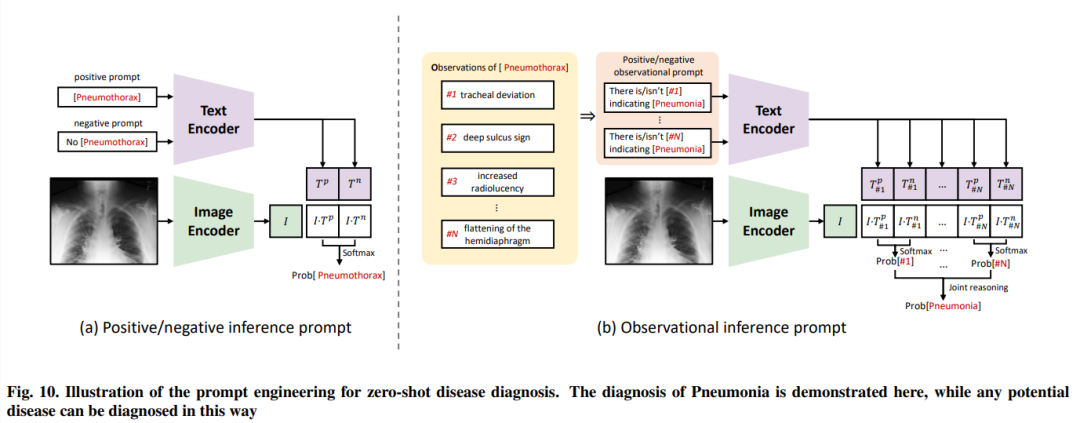 图10. 对于零样本疾病诊断的提示工程进行说明。这里演示了对肺炎的诊断,然而,任何潜在的疾病都可以通过这种方式进行诊断。
图10. 对于零样本疾病诊断的提示工程进行说明。这里演示了对肺炎的诊断,然而,任何潜在的疾病都可以通过这种方式进行诊断。
4.1.2 上下文优化
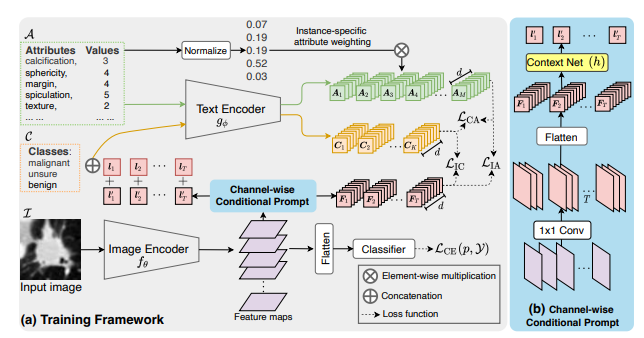
4.2 密集预测
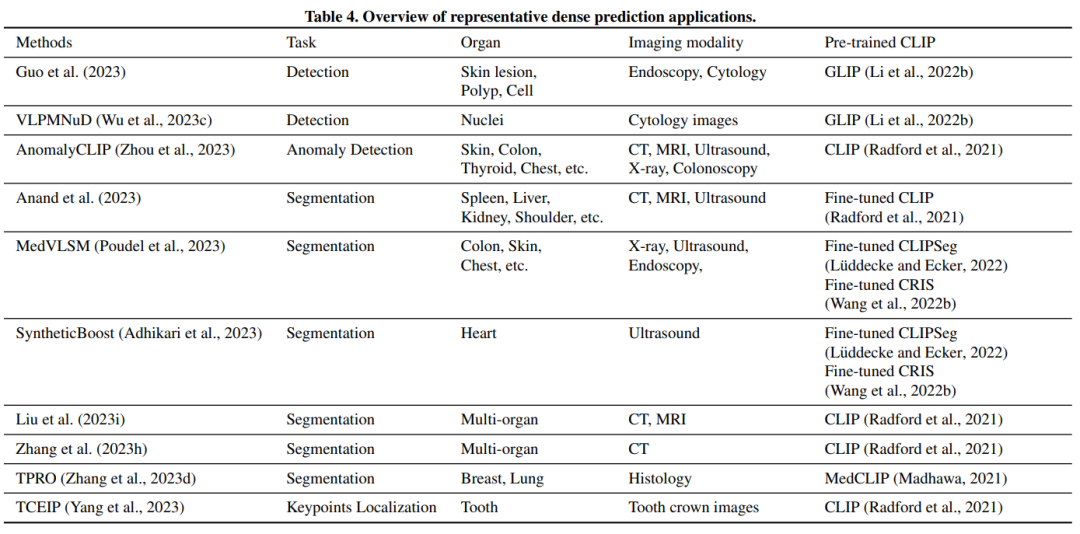 表4. 代表性密集预测应用概述。
表4. 代表性密集预测应用概述。
4.2.1 检测
4.2.2 2D医学图像分割
4.2.3 3D医学图像分割
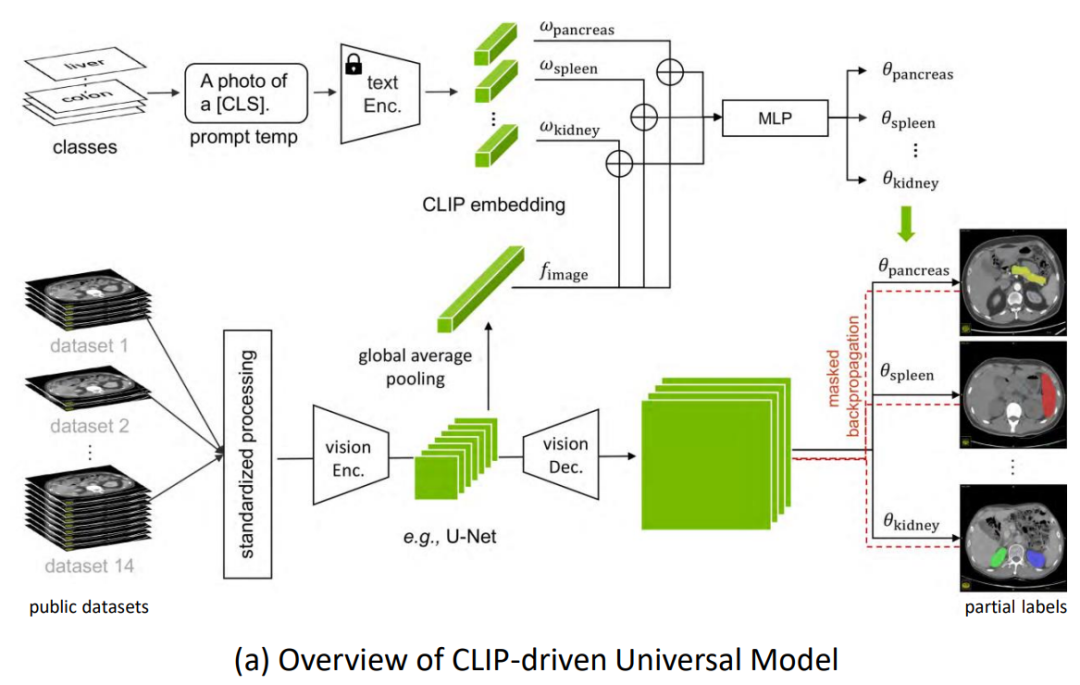
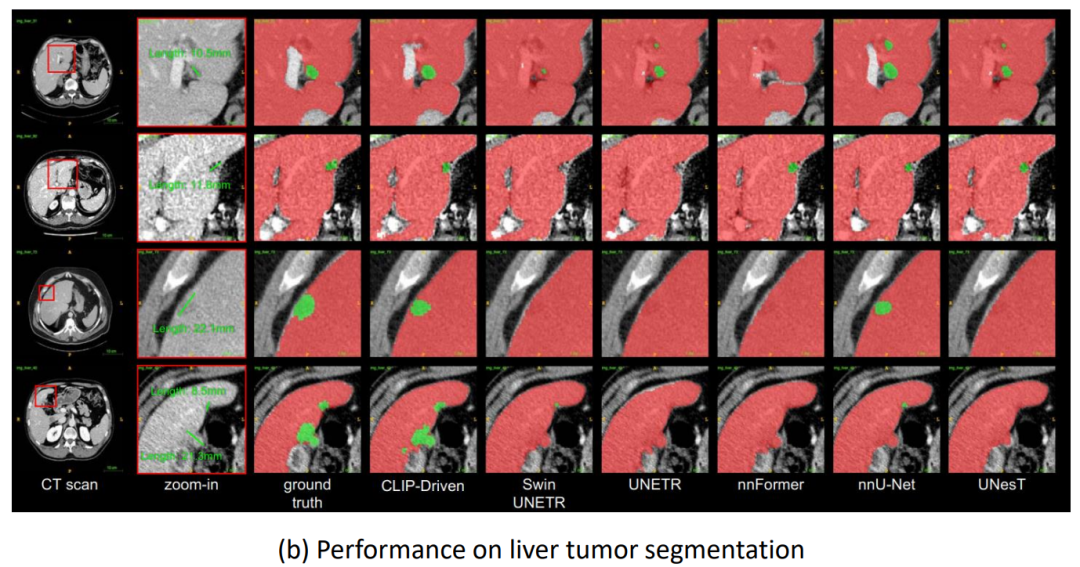
4.2.4 其他任务
4.3 跨模态
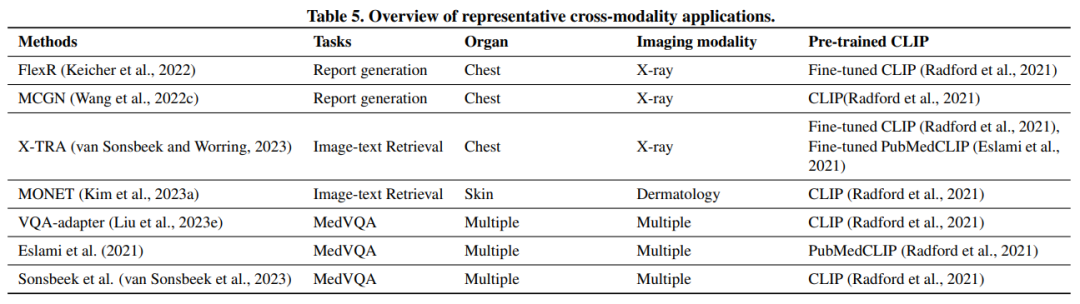 表5. 典型的跨模态应用概述。
表5. 典型的跨模态应用概述。
4.3.1 报告生成
4.3.2 医学视觉问答
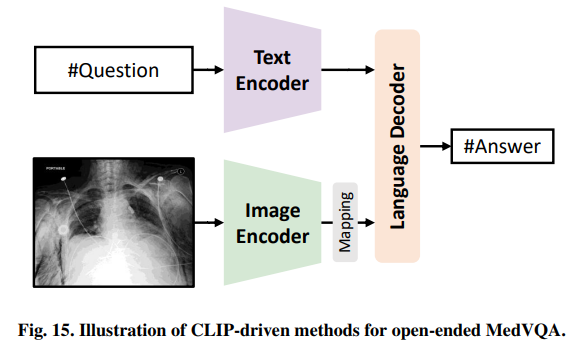 图15. 开放式MedVQA的clip驱动方法的说明
图15. 开放式MedVQA的clip驱动方法的说明
4.3.3 图像文字检索
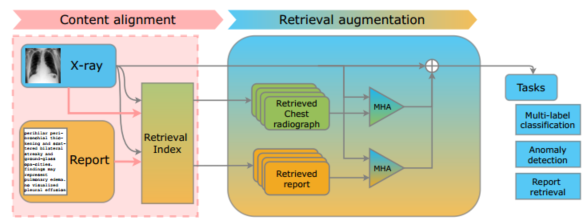
4.4 总结
5 讨论与未来工作方向
-
预训练和应用之间的不一致。 -
精细化预训练评估不全面。 -
精细 CLIP 预训练的范围有限。 -
探索元数据的潜力。 -
合并高阶相关性。 -
超越图像-文本对齐。
6 结论
6 结论


本篇文章来源于微信公众号: 医工学人
