








该文章提出了一系列可扩展且具有良好迁移能力的U-Net模型——STU-Net,其参数规模范围从1400万到14亿。值得注意的是,具有14亿参数的STU-Net是目前最大的医学图像分割模型。他们的 STU-Net 基于 nnU-Net 框架,由于其应用广泛和出色的性能。他们首先优化了 nnU-Net 默认的卷积块,使它们具有可扩展性。然后,我们经验性地评估了不同的网络深度和宽度的扩展组合,发现同时扩大模型的深度和宽度是最优的。首先,他们在大规模的 TotalSegmentator 数据集上训练不同大小的STU-Net模型,并发现增加模型大小可以带来更强的性能。这意味着在医学图像分割领域,大规模模型有着巨大的潜力。此外,他们评估了模型在14个下游数据集的直接推理及3个数据集的微调性能,包括不同的图像模态和分割任务。结果显示,文章提出的预训练模型无论是在直接推理还是微调上都有出色的表现。
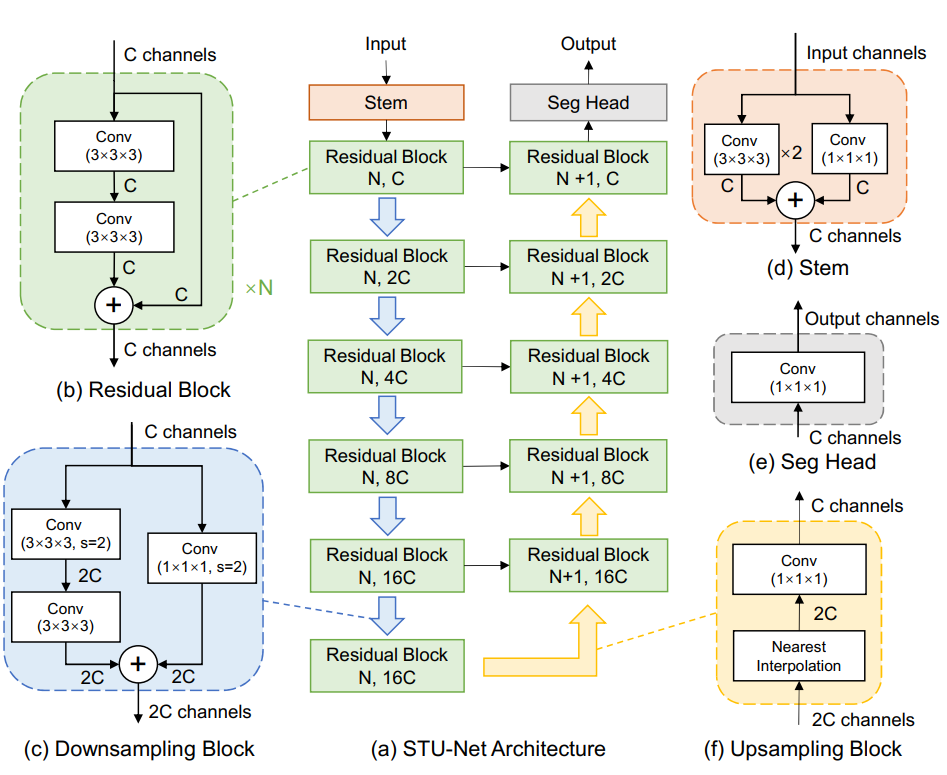
图1:STU-Net 结构示意图,基于 nnU-Net 对一些模块进行修改,使其具有迁移性和可扩展性。
01
超参数的设置

图2:对比 STU-Net 和 nnU-Net, 3D U-Net 之间的超参数设置。
02
调整基本模块
为了解决这个问题,我们在基础块中引入了残差连接。此外,为了使整个架构更加紧凑,我们还将降采样集成到每个阶段的第一个残差块中。这种降采样块具有与常规残差块相似的残差架构,由左、右两个分支组成,其中左分支有两个不同步长的 3×3×3 卷积,而右分支使用步长为 2 的 1×1×1 卷积核。这种基础块的改进使得整个架构更加紧凑,同时还能解决梯度扩散的问题。
03
调整上采样模块
为了解决这个问题,我们使用插值 (interpolation) 加上一个步长为 1 的 1×1×1 卷积层来替代转置卷积。这种权重自由的插值方法可以解决权重形状不匹配的问题。我们使用最近邻插值 (nearest neighbor interpolation) 来进行上采样,实验结果表明,最近邻插值不仅速度更快,而且还能够达到与双立方插值 (cubic linear interpolation) 相当的性能。
04
缩放策略
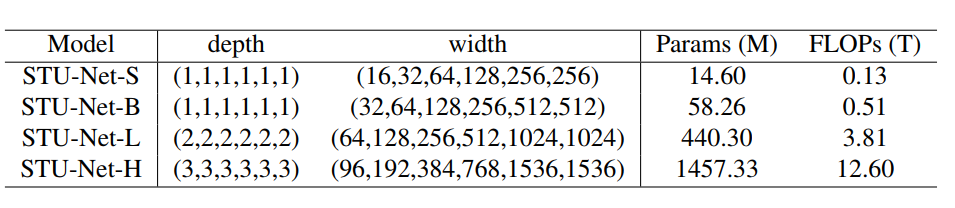
为了简化缩放问题,我们采用了对称结构的模型,即同时缩放编码器和解码器,并在每个分辨率阶段中以相同的比例缩放深度和宽度。图 3 展示了 STU-Net 的不同规模,其中后缀“S,B,L,H”分别表示 “Small, Base, Large, Huge”。
基于 TotalSegmentator
大规模有监督预训练 STU-Net
实验结果
01
在大规模数据集上,更大的模型具有更好的性能
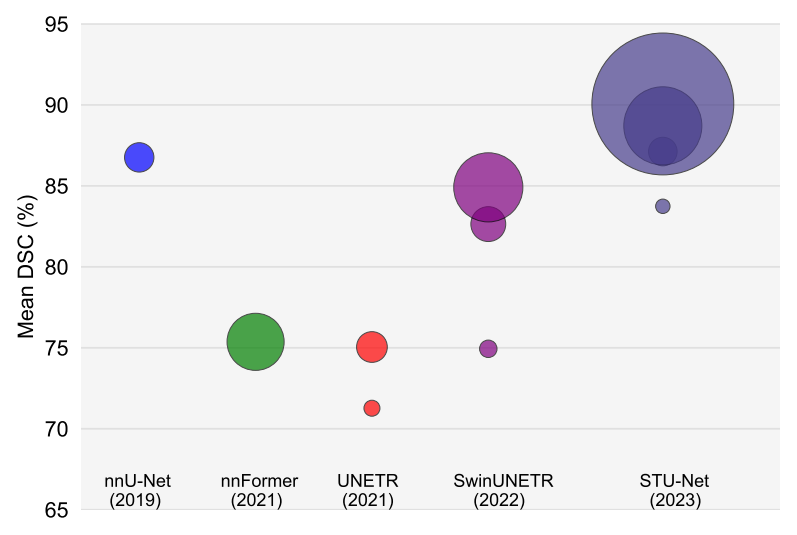
图4:在 TotalSegmentator 上对比不同模型的性能。气泡的大小与模型的计算量相关,不同的颜色代表不同的模型,同一种颜色的不同大小的气泡对应同一种模型的不同尺寸。
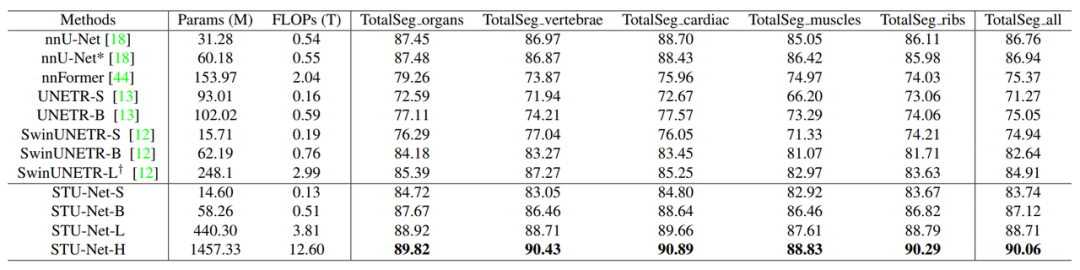 图5:不同模型在 TotalSegmentator 数据集上五个子类别和所有类别上平均性能对比。
图5:不同模型在 TotalSegmentator 数据集上五个子类别和所有类别上平均性能对比。
02
经过大模型预训练,更大的模型具有更好的泛化性
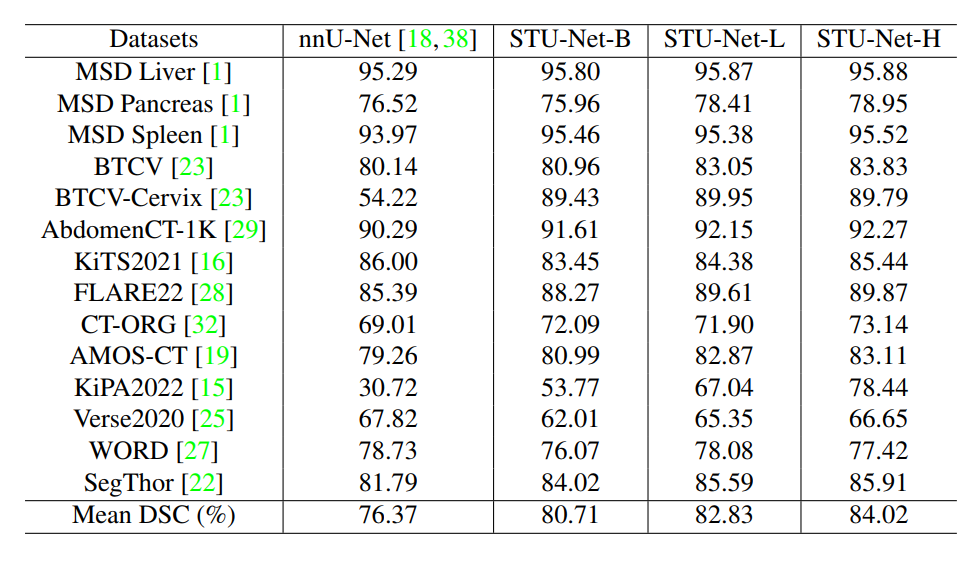 图6:大规模数据集上,更大的模型具有更好的跨数据集泛化性。
图6:大规模数据集上,更大的模型具有更好的跨数据集泛化性。
03
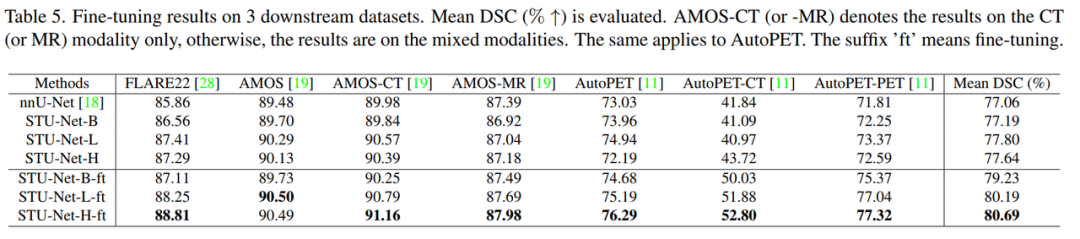
大规模有监督预训练有效,更大的模型具有更好的迁移性
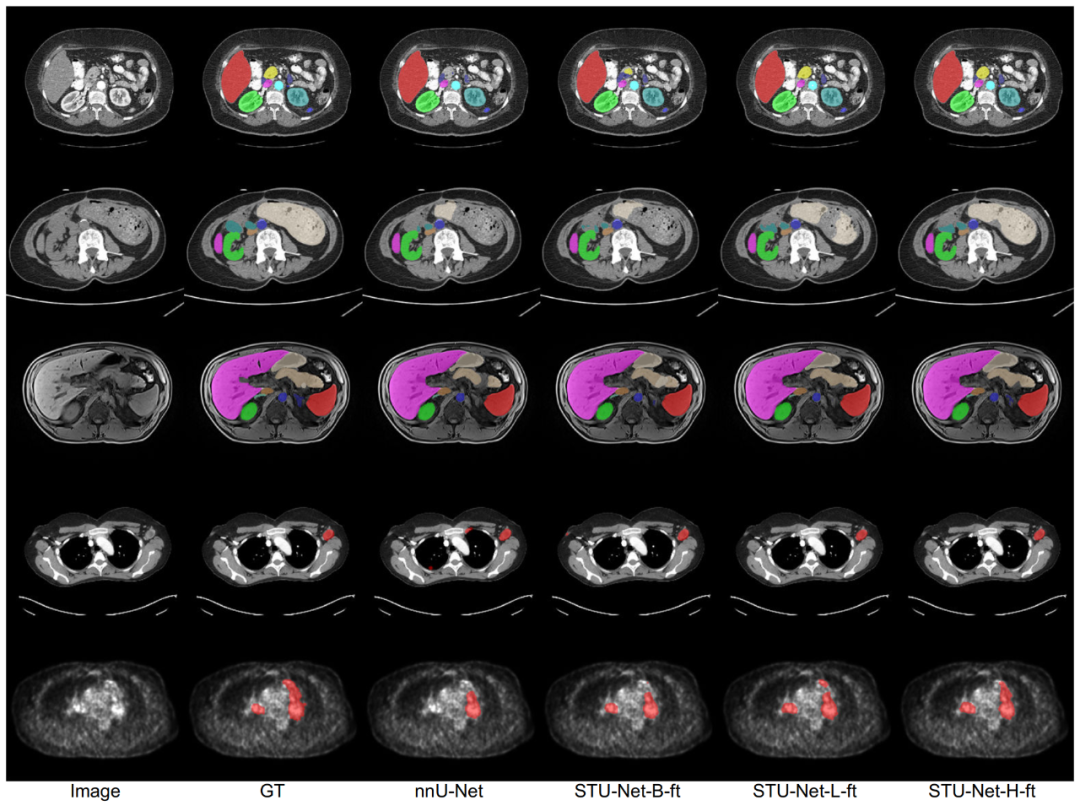
04
更大的模型具有更高效的数据利用率
我们对比了使用不同比例的 TotalSegmentator 训练数据训练的不同大小的 STU-Net,更大的模型具有更好的数据利用率,使用少量的训练数据即可达到小模型使用大量数据训练的性能。
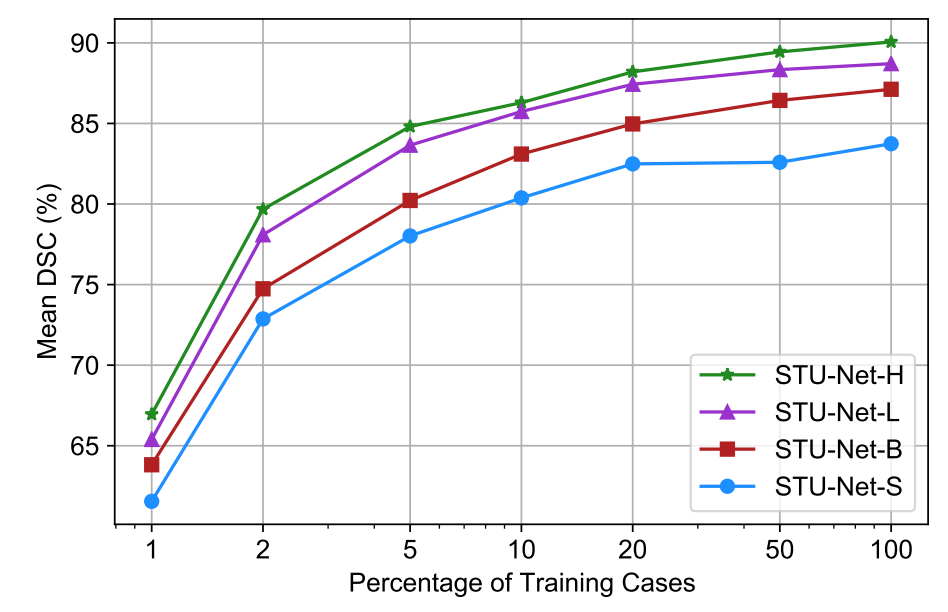 图9:对比不同大小的模型在不同比例训练数据下的性能。更大的模型只需要少量训练数据,即可取得与小模型在大量训练数据下的性能。
图9:对比不同大小的模型在不同比例训练数据下的性能。更大的模型只需要少量训练数据,即可取得与小模型在大量训练数据下的性能。
04
更大的模型更适合用作通用模型
我们将 TotalSegmentator 的 104 类分为 5 大子类,对比训练一个通用模型同时分割 104 类和 5 个专家模型共同分割 104 类的效果。实验结果可以看到,更大的模型更适合作为一个通用模型,且性能优于多个专家模型。
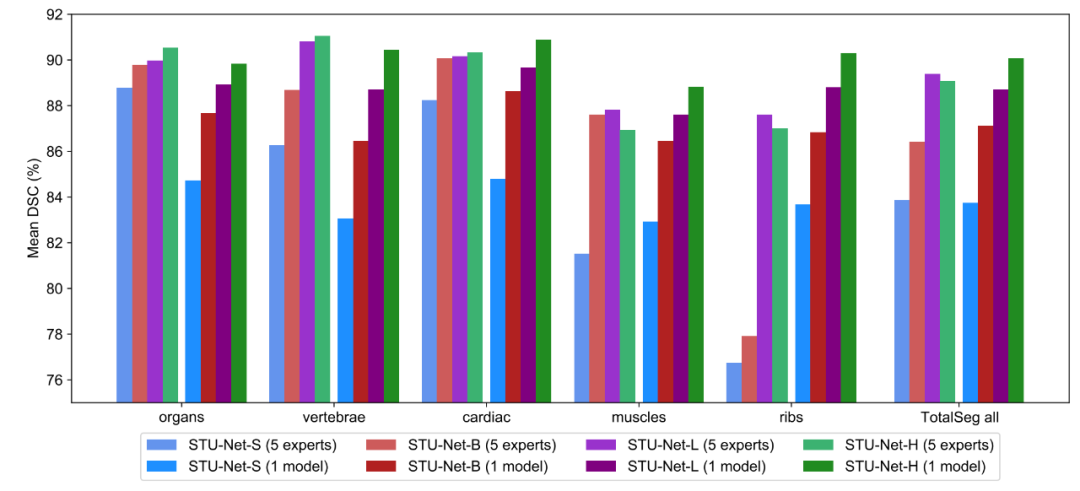
图10:通用模型和专家模型的对比。
总结
本文介绍了一种基于 nnU-Net 框架的可扩展和可转移的医学图像分割模型 STU-Net。STU-Net 最大包含 14 亿个参数,是迄今为止最大的医学图像分割模型。通过在大规模的 TotalSegmentator 数据集上训练 STU-Net 模型,我们证明了模型规模的扩展在迁移到各种下游任务时产生了显著的性能提升,同时这验证了大模型在医学图像分割领域的潜力。此外,STU-Net-H 模型在 Total Segmentator 数据集上训练,在多个下游数据集中表现出强大的直接推断和微调可迁移性。这一观察结果强调了利用大规模预训练模型进行医学图像分割任务的实际价值。总之,可扩展和可转移的 STU-Net 模型的发展有望推动医学图像分割技术的发展,为医学图像分割社区的研究和创新开辟了新的途径。
END
编辑 | 刘帅
来源 | 通用医疗GMAI
审核 | 医工学人


本篇文章来源于微信公众号: 医工学人
